
Modélisation des données : définitions, types, exemples et bonnes pratiques (2025)
Découvrez la modélisation des données : définitions, types, modèles relationnel et NoSQL, bonnes pratiques et outils pour data engineers

Introduction à la modélisation des données
La modélisation des données est l’une des compétences les plus utiles à acquérir dans le domaine de la data. Elle permet de donner une structure claire à l’information, de rendre les systèmes plus simples à comprendre et à faire évoluer, et d’éviter les erreurs qui coûtent du temps et de l’argent.
Apprendre à modéliser, c’est apprendre à organiser les données de façon à ce qu’elles soient fiables, cohérentes et prêtes à être exploitées. C’est ce qui fait la différence entre un projet qui avance vite et un projet qui s’enlise dans des corrections et des ajustements sans fin.
Que l’objectif soit de créer un tableau de bord pertinent, d’automatiser un pipeline ou simplement de mieux comprendre comment circulent les données, cette compétence ouvre la porte à des analyses plus justes, à des décisions plus rapides et à des systèmes plus solides.
Dans un monde où les données se multiplient et où les besoins changent rapidement, savoir modéliser, c’est poser des bases solides pour tout projet, quel que soit son niveau de complexité.
Qu’est-ce que la modélisation des données ?
La modélisation des données est le processus qui consiste à représenter de manière organisée les informations d’un système.
Elle décrit quelles données existent, comment elles sont structurées et comment elles interagissent entre elles.
Cette représentation peut être visuelle (schéma) ou textuelle (documentation), et sert de référence commune à toutes les personnes qui travaillent sur un projet : data engineers, analystes, développeurs, mais aussi équipes métier.
L’objectif est simple : rendre les données compréhensibles et exploitables.
Sans modélisation, les données peuvent vite devenir un ensemble confus, difficile à maintenir et à faire évoluer.
Avec un modèle clair, il devient plus facile de :
- Identifier les relations entre les différentes entités (clients, produits, transactions, etc.).
- Garantir la cohérence et la qualité des données.
- Optimiser les performances des requêtes et des analyses.
- Faciliter la communication entre équipes techniques et métiers.
On peut comparer la modélisation des données à la conception d’un bâtiment.
Avant de poser la première pierre, un architecte définit un plan : chaque pièce est identifiée, ses dimensions sont précises, et les connexions entre elles sont claires.
Dans une organisation data, c’est la même logique : chaque “pièce” correspond à une entité (par exemple un salarié), et chaque entité possède ses propres “mesures” ou attributs : nom, prénom, âge, adresse…
Ce plan détaillé permet à tous les acteurs du projet de savoir exactement où se trouvent les informations, comment elles s’articulent, et comment les utiliser efficacement.
Les niveaux de modélisation : conceptuel, logique, physique
La modélisation des données s’effectue classiquement selon trois niveaux d’abstraction, correspondant chacun à une étape et à une audience spécifique.
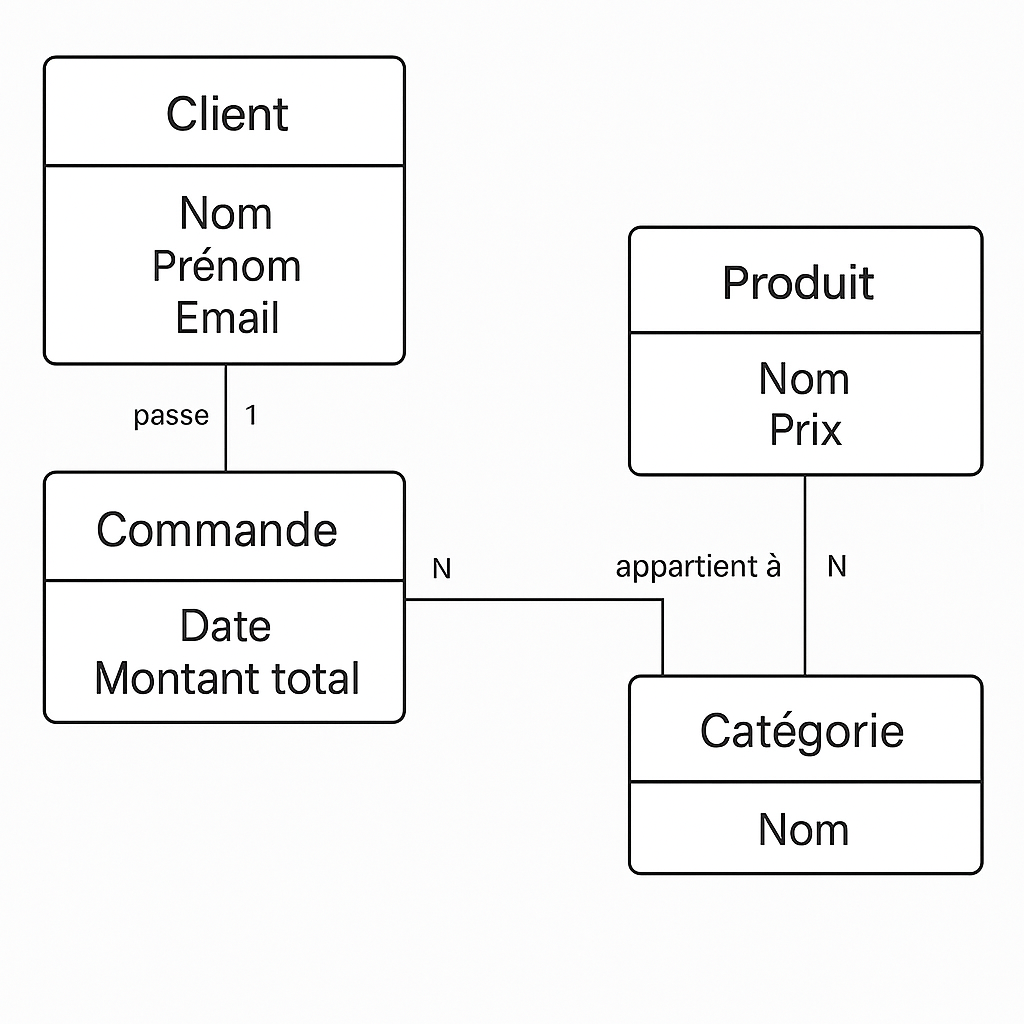
Modèle Conceptuel de Données (MCD)
Le modèle conceptuel est une représentation abstraite, visuelle et universelle des données. Il répond à la question « Quoi ? » : quelles sont les entités du métier (client, produit, commande…), leurs attributs (nom, email, prix), et leurs relations (un client passe plusieurs commandes). Il ignore totalement les contraintes techniques ou les spécificités des SGBD.
Ce modèle sert à :
- Cartographier les objets métier et leurs interactions.
- Fédérer la compréhension entre métiers, analystes et techniciens.
- Valider la couverture des processus métier.
Son schéma de référence est le diagramme entité-association (DEA). Des outils comme Escalidraw.com, dbdiagram.io, ou Lucidchart sont recommandés pour concevoir rapidement un MCD partageable.
Modèle Logique de Données (MLD)
Le modèle logique traduit le conceptuel en notions informatiques : il structure l’information selon les standards relationnels (tables, clés primaires/étrangères, types), ou NoSQL (collections, documents, graphes). Il reste indépendant du moteur ou du SGBD employé.
- Détail des entités : quelles colonnes, quels types de données, quelles clés.
- Précision des relations : cardinalités (un-à-un, un-à-plusieurs, plusieurs-à-plusieurs).
- Définition des contraintes d’intégrité, de normalisation jusqu’à la 3NF.
Le MLD est la base de la conception de schémas (SQL, JSON, etc.). Outils recommandés : Lucidchart, dbdiagram.io, Eraser – AI
Modèle Physique de Données (MPD)
Le modèle physique est la déclinaison opérationnelle du modèle logique pour un SGBD donné (PostgreSQL, Oracle, MongoDB, etc.). Il spécifie :
- Les tables concrètes, collections, nœuds.
- Les types exacts, tailles, index, partitions, tablespaces.
- Les contraintes d’intégrité, triggers, vues matérialisées, paramètres de performance.
Le MPD est essentiel pour optimiser l’implémentation, garantir la cohérence et la rapidité des requêtes. Des outils comme Erwin Data Modeler, MySQL Workbench, ou des plateformes SaaS permettent de générer rapidement des MPD à partir de modèles logiques validés.
Tableau récapitulatif : différences clés entre MCD, MLD et MPD
| Niveau | Objectif | Cible | Représentation |
|---|---|---|---|
| Conceptuel (MCD) | Abstraction, partage métier | Métiers, analystes | Diagramme entité-assoc. |
| Logique (MLD) | Structuration technique indépendante | Architectes data | Schéma relationnel/ERD |
| Physique (MPD) | Implémentation réelle, optimisation | DBA, dév. SGBD | Tables, types, index, SQL |
Suivant ce triptyque, une modélisation robuste est assurée, depuis la vision métier jusqu’à la performance sur l’infrastructure technique.
Grands types de modèles de données et architectures associées
L’univers de la modélisation ne se limite plus au seul modèle relationnel. Plusieurs paradigmes répondent à des besoins spécifiques, et le choix dépend du contexte d’usage, du volume, du type de données et des objectifs analytiques ou opérationnels.
Le modèle relationnel
Le modèle relationnel, structure les données en tables (relations) interconnectées via des clés primaires et étrangères.
Caractéristiques-clés :
- Structuration en tables à colonnes et tuples.
- Intégrité référentielle (clé primaire/étrangère).
- Algèbre relationnelle (jointures, projections, sélections).
- Normalisation pour réduire la redondance.
Le relationnel demeure la norme pour les applications transactionnelles, les référentiels structurés et l’exploitabilité via SQL. Il garantit la cohérence et l’interopérabilité, mais peut atteindre ses limites sur de très gros volumes ou des données faiblement structurées.
Schéma en étoile (Star Schema)
Le schéma en étoile est la base de la modélisation dimensionnelle utilisée en data warehousing et BI. Il comprend :
- Une table de faits centrale, contenant les mesures (ventes, quantités, etc.).
- Plusieurs tables de dimensions (temps, produit, client, magasin…), liées directement à la table de faits.
Atouts : simplicité de navigation, rapidité pour l’analytique OLAP, logique d’interrogation intuitive pour les analystes.
Limites : redondance potentielle dans les dimensions ; peu flexible pour évolutions de structure.
Cas d’usage typiques :
- Analyse des ventes : suivi des revenus par période, par produit, par région ou par canal de distribution.
- Reporting marketing : mesure de l’efficacité des campagnes publicitaires en croisant les dimensions temps, canal et segment client.
- Suivi de la performance magasin : comparaison des ventes et marges entre différents points de vente ou zones géographiques.
- Analyse logistique : suivi des volumes expédiés, délais de livraison et coûts par fournisseur ou entrepôt.
- Pilotage e‑commerce
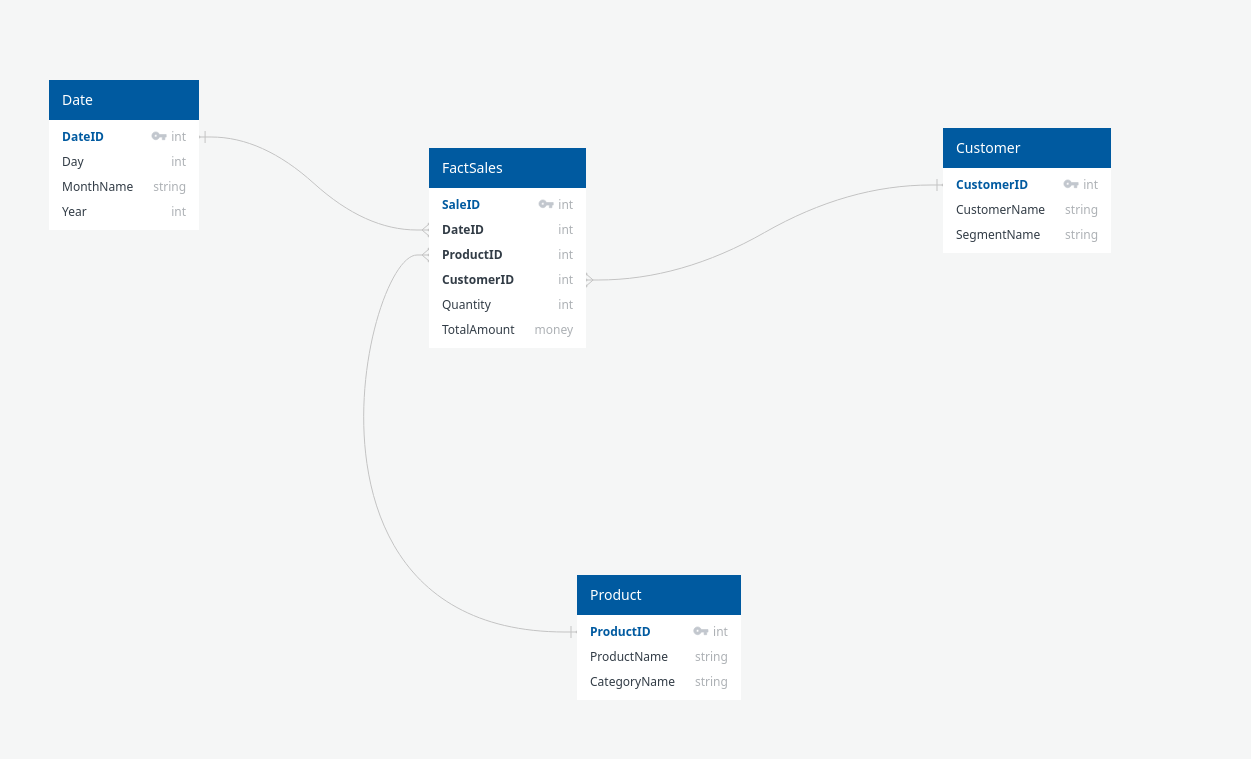
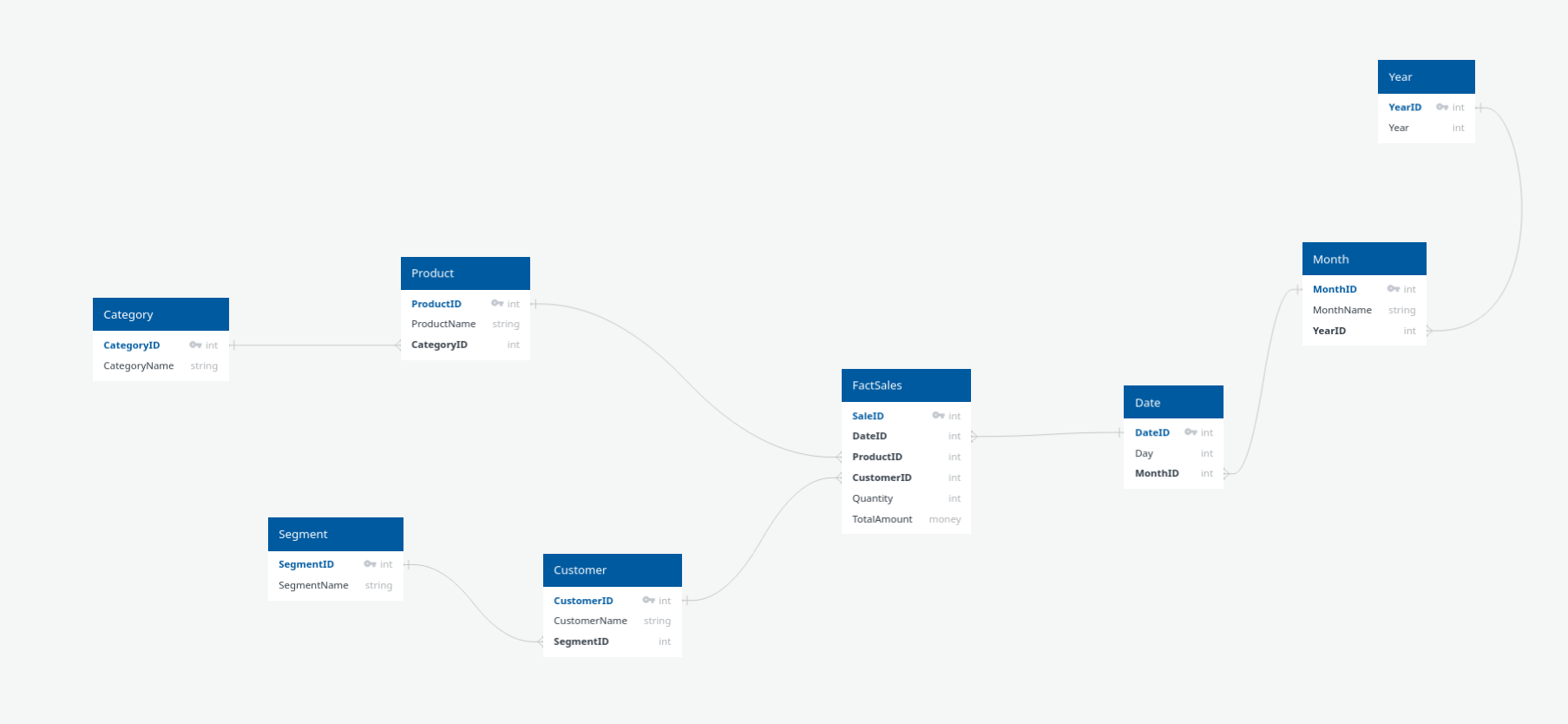
Schéma en flocon de neige (Snowflake Schema)
Le schéma en flocon est une version normalisée du schéma en étoile : les dimensions sont elles-mêmes décomposées en sous-dimensions, réduisant la redondance mais complexifiant les requêtes.
- Meilleure efficacité du stockage pour les architectures massives.
- Performance potentiellement moindre en lecture (plus de jointures).
- Utile pour des dimensions très complexes, avec hiérarchies multiples.
Comparatif étoile vs flocon (tableau synthétique)
| Critère | Schéma Étoile | Schéma Flocon |
|---|---|---|
| Redondance | Élevée | Faible |
| Jointures | Peu (rapides) | Nombreuses (lentes) |
| Simplicité requêtes | Simple (utilisateurs) | Complexe (avancé) |
| Flexibilité | Moyenne | Haute |
| Espace disque | Plus important | Réduit |
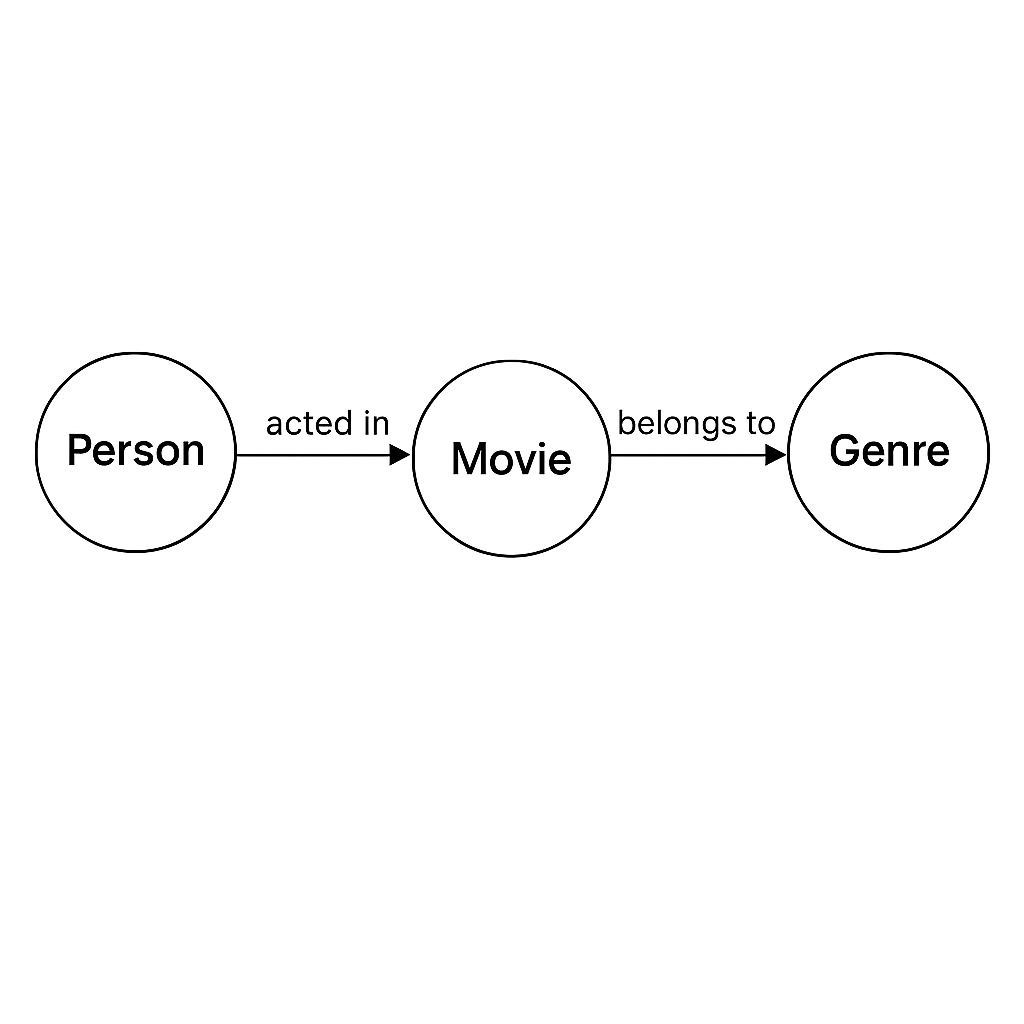
Modélisation par graphes
Les bases de données graphe (Neo4j, OrientDB, etc.) gagnent du terrain pour modéliser les relations complexes à n niveaux (réseaux sociaux, parcours client, IT, interactions biologiques).
- Données organisées en nœuds et arêtes, chaque entité ou relation peut porter ses propres propriétés.
- Traversées rapides sur de grands graphes là où les requêtes SQL impliquer des jointures coûteuses.
- Adaptées pour la détection de fraudes, la gestion des réseaux logistiques, la connaissance métier (knowledge graph).
Modélisation documentaire (NoSQL)
Les modèles NoSQL orientés document (MongoDB, CouchDB…) privilégient la souplesse et la scalabilité en organisant les données sous forme de documents JSON (ou BSON), regroupés en collections.
- Documents pouvant adopter des structures variées.
- Parfaits pour l’enregistrement de logs, de profils utilisateurs, de données semi-structurées (applications mobiles, IoT).
- Impliquent souvent une dénormalisation pour optimiser la lecture.
Modèle hybride et architecture polyglotte
L’architecture hybride/polyglotte combine plusieurs modèles, adaptant la structure à chaque cas d’usage.
- Entrepôt central (data warehouse OLAP) en schéma en étoile.
- Application transactionnelle en modèle relationnel.
- Base documentaire pour logs ou catalogues.
- Graphe pour relations d’objets complexes.
Cette approche permet d’optimiser performance et pertinence métier, au prix d’une gouvernance plus exigeante (gestion des synchronisations et des conversions de modèles).
Bonnes pratiques de modélisation des données
Collaborer en amont avec les parties prenantes
Avant même de dessiner la première entité, mets tout le monde autour de la table : métiers, analystes, développeurs, data stewards.
Exemple : sur un projet e‑commerce, comprendre que “client” peut désigner à la fois un acheteur ponctuel et un compte entreprise change complètement la structure du modèle. Sans ce dialogue, tu risques de créer un schéma qui ne colle pas aux usages réels.
Éliminer la redondance : la normalisation
La normalisation, c’est comme ranger un atelier : chaque outil (ou donnée) a sa place.
- Avantage : moins de doublons, plus de cohérence.
- Exemple : au lieu de stocker l’adresse complète du client dans chaque commande, tu la mets dans une table
Clientet tu fais référence à son ID. - Limite : dans un tableau de bord Power BI, 8 jointures pour afficher un simple rapport de ventes peuvent vite plomber les performances.
Dénormaliser pour l’analytique ou NoSQL
En analytique, parfois, on préfère un “plan de travail” encombré mais où tout est à portée de main.
- Exemple : dans un data mart marketing, tu peux dupliquer le nom du produit et la catégorie directement dans la table des ventes pour éviter des jointures coûteuses.
- Bonne pratique : documenter chaque dénormalisation et prévoir comment synchroniser les données si la source change.
Penser évolutivité et flexibilité
Un modèle figé, c’est un piège.
- Exemple : utiliser des UUID plutôt qu’un simple entier auto‑incrémenté permet d’intégrer plus tard des données venant d’autres systèmes sans risque de collision.
- Laisser des champs optionnels ou prévoir des tables “extension” peut sauver des semaines de refonte quand un nouveau besoin arrive.
Documenter, versionner, maintenir
Un modèle sans documentation, c’est comme un plan de métro sans légende.
- Exemple : un dictionnaire de données clair, avec pour chaque champ : définition métier, type, contraintes, exemple de valeur.
- Outils : Git pour versionner les schémas, dbt pour intégrer la doc directement dans les workflows.
Assurer la qualité et la gouvernance
- Exemple : un test automatique qui bloque le déploiement si une table contient des valeurs NULL dans une colonne censée être obligatoire.
- Outils : Great Expectations ou Soda Core pour surveiller la qualité en continu.
Éviter les erreurs fréquentes
- Sur‑modéliser : créer 15 tables pour un besoin qui en demande 3.
- Oublier les clés primaires/étrangères : bonjour les doublons et incohérences.
- Dénormaliser “par confort” sans documenter : tu te retrouves avec des données divergentes au bout de 6 mois.
- Ignorer la volumétrie : une table de logs qui grossit sans limite peut exploser ton stockage.
En résumé : un bon modèle, c’est un équilibre entre rigueur et pragmatisme. On garde la structure propre, mais on sait aussi plier les règles quand la performance ou la lisibilité l’exige — et on explique toujours pourquoi.
Conclusion
Faire un bon schéma de données, c’est préparer le terrain pour aller vite et bien. Un modèle clair aide toute l’équipe à comprendre le projet, à communiquer et à intégrer de nouveaux développeurs rapidement, même des juniors.
Il faut savoir simplifier quand c’est nécessaire, découper les gros schémas en parties plus petites, et garder la complexité seulement là où elle apporte vraiment de la valeur. Avec cette approche, on gagne du temps, on évite les blocages et on livre plus vite des résultats utiles.
Questions fréquentes
Autres articles

Azure Key Vault : sécuriser vos secrets dans le cloud
Comprendre, évaluer et intégrer Azure Key Vault pour protéger secrets, clés et certificats. Cas d’us...

Déployer une application FastAPI sur Azure Web App avec Azure CLI, Docker et GitHub Actions
Tutoriel complet pour déployer une application FastAPI sur Azure Web app en utilisant Docker, Azure ...